CS5446 6. Stochastic approximation
Notes for CS5446 Reinforcement Learning.
如何优化采样估计
一般的采样估计要求我们拿到所有的值后才能计算平均。那有没有一种办法 incremental update 呢?
$$ w_{k+1} = \frac{1}{k}\sum_{i=1}^{k}x_i, k=1,2,\dots \\\\ w_{k} = \frac{1}{k=1}\sum_{i=1}^{k-1}x_i, k=2,3,\dots $$这两个式子表示当我们拿到第k个数后计算mean的公式,那么我们可以得到一个递推公式:
$$ w_{k+1} = w_k - \frac{1}{k}(w_k-x_k) $$这个递推公式为我们提供了迭代求解 mean 的办法。它的缺点在于刚开始的时候误差比较大。
这个式子可以进行推广,第二项的 $\frac{1}{k}$ 是可以替换为满足某些条件的 $\alpha_k$ :
$$ w_{k+1} = w_k - \red{\alpha_k}(w_k-x_k) $$这个算法就是一种 stochastic approximation 的算法。SA 算法指的是一类$(1)$ 对一些变量进行采样$(2)$ 可以通过迭代的方式进行求解或者优化的算法。
SA 的优势在于它可以在不知道原方程的基础上直接对原方程进行求解。
其实是一种问题转换。比如求解 $g(x) = 0$ , 我们可以把它转化为求 $f(x) = \frac{1}{2}(g(x))^2$ 的最小值。然后我们就可以通过多种方式尝试进行求解。
这个时候 $f(x)$ 就是 $g(x)$ 的目标函数
Robbins-Monro algorithm
对于一个问题 $g(w) = 0$ 我们要求解这个问题。我们可以用以下公式进行求解:
$$ w_{k+1} = w_k - a_k(g(w_k) + \eta_k), \quad k=1,2,3,\dots $$其中:
- $w_k$ 是对解的第 k 次估计
- $a_k$ 是一个系数
- $g(w_k)$ 是对 $g(w)$ 的第k次观测,$\eta_k$ 是噪音。$(g(w_k) + \eta_k)$ 就是对 $g(w)$ 的第k次带噪音的观测
example
一个使用RM来求解的例子:
$$ g(w) = \tanh(w - 1) = 0 \\\\ \text{Parameters: } w_1 = 3, a_k = 1/k $$这个例子里我们不考虑噪音。那么迭代式子就变成了:
$$ w_{k+1} = w_k - a_kg(w_k) $$我们不断把结果代入进去:
import math
ITERATION = 100
w = 3
for k in range(1, ITERATION):
w = w - 1/k*math.tanh(w-1)
print(f"w_{k+1}: {w:.4f}")
我们可以看到结果:
w_2: 2.0360
w_3: 1.6478
w_4: 1.4578
w_5: 1.3507
w_6: 1.2833
w_7: 1.2373
w_8: 1.2040
w_9: 1.1789
...
w_99: 1.0147
w_100: 1.0145
我们就通过迭代的方式求解出来了 $g(w) = 0$ 的根也就是 $w^* = 1$ .这个和我们对解析解的分析是一致的。
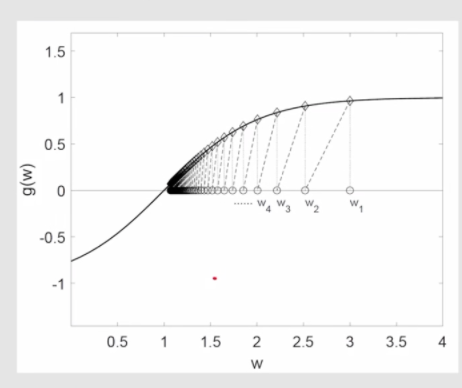
这个图展示了它的收敛方式。
restriction
我们重新回到 RM 的公式:
对于一个问题 $g(w) = 0$ 我们要求解这个问题。我们可以用以下公式进行求解:
$$ w_{k+1} = w_k - a_k(g(w_k) + \eta_k), \quad k=1,2,3,\dots $$其中:
- $w_k$ 是对解的第 k 次估计
- $a_k$ 是一个系数
- $g(w_k)$ 是对 $g(w)$ 的第k次观测,$\eta_k$ 是噪音。$(g(w_k) + \eta_k)$ 就是对 $g(w)$ 的第k次带噪音的观测
这个求解公式不总是成立,它的成立条件是:
- 对于问题 $g(w)$
,要求:
- $g$ 是单调递增的。只有单调递增才有解
- $g$ 的 gradient 必须是有上界的,这保证算法可以收敛
- 对于$a_k$
要求:
- $\sum^\infty_{k=1} a_k^2 < \infty$ : 保证 $a_k$ 是收敛到 0 的。这一点保证了 $w_{k+1} - w_{k}$ 趋向于0,也就是说它稳定了。
- $\sum^\infty_{k=1} a_k = \infty$ :保证 $a_k$ 不会收敛得太快。这一点保证了无论我们选什么值作为 w 的初始值,它最终都会在解上收敛。
- 对噪音,或者测量误差 $\eta_k$
的要求
- $\eta_k$ 的 mean = 0
- $\eta_k$ 的 mean 是有界的
对于 $a_k$ 的取值,$1/k$ 是一个很好的例子,但是我们经常用一个小常数。因为 $1/k$ 会导致后来的数据起的作用很小。
Stochastic gradient descent
随机梯度下降(SGD)是一种特殊的 RM 算法。它主要解决一类优化问题,其中期望就是优化问题,因此我们可以把 SGD 写成这种形式:
对于某个待求解问题 $f(w, X)$ 我们有针对对它的一个目标函数 $J(w)$ 我们希望它尽可能小:
$$ \min_{w} J(w) = \mathbb{E}[f(w,X)] $$- X 是随机变量,服从某种分布
- Expectation 是对 X 进行求的,我们的目标是找到一个 w 使得 E 最小
为了解这个优化问题,我们可以使用 SGD 递推出来:
$$ w_{k+1} = w_k - \alpha_k \nabla_w f(w_k,x_k) $$example
$$ \min_w J(w) = \mathbb{E}[f(w, X)] = \mathbb{E}\left[\frac{1}{2}\|w-X\|^2\right] $$ $$ f(w,X) = \frac{1}{2}\|w - X\|^2, \quad \nabla_w f(w, X) = w - X $$X 是采样所得的结果,这个问题是期望这个估计 w 和 X 的距离最小。可以很容易知道,$w^* = \mathbb{E}[X]$
我们来看如何使用 SGD 解的方式:
$$ w_{k+1} = w_k - \alpha_k(w_k - x_k) $$如果我们给定一个 $\alpha_k$ 就可以直接迭代求解。
BDG & MBDG & SGD
batch gradient descent (BGD) 和 mini-batch gradient descent (MBDG) 是 SGD 的 batch 版本。我们依旧来看这个问题,看看BGD、MBDG和SGD是如何解决这个问题的:
对于某个待求解问题 $f(w, X)$ 我们有针对对它的一个目标函数 $J(w)$ 我们希望它尽可能小:
$$ \min_{w} J(w) = \mathbb{E}[f(w,X)] $$- X 是随机变量,服从某种分布
- Expectation 是对 X 进行求的,我们的目标是找到一个 w 使得 E 最小
- BGD: 每次用n个所有的采样,在这个基础上求平均
- 最接近真实的的期望
- MBGD: 比如每次有1 million 个采样结果,但是每次只用100个采样结果来求平均
- $\mathcal{I}_k$ 是第 k 次采样的索引集合, 也就是100个数据的集合
- 在这组数据上做平均
- SGD: 每次只用一个采样结果来进行计算
MBGD 是 BGD 和 SGD 的超集。
- 相对于 SGD,MBGD 的随机性更小;
- 相对于BGD 计算量更小。
- 当 MBGD 的 batch size 和 BGD 的 batch size 一样的时候,他们两个仍然有细微区别。 MBGD 是从数据集中随机采样出来的,而 BGD 是用的所有的数据。