CS5446 4. Value iteration & Policy iteration
Notes for CS5446 Reinforcement Learning.
Value iteration
$$ v_{k+1} = f(v_k) = max_{\pi} (r_{\pi} + \gamma P_{\pi}v_k), k = 0, 1, 2, ... $$求解步骤:
- Step 1: policy update
- $v_{k}$ 会被给出,初始状态下我们会给一个任意的值
- 我们会根据 $v_{k}$ 来更新 policy
- 我们会得到一个 $\pi_{k+1} = \arg \max_{\pi} r_{\pi} + \gamma P_{\pi}v_k$
- Step 2: value update
- 当我们有了新的 policy 之后,我们就可以根据新的 policy 来更新 value
- 我们会得到一个 $v_{k+1} = r_{\pi_{k+1}} + \gamma \blue{ P_{\pi_{k+1}}}v_k$
- 这样我们就得到了新的 value 值,就可以代入到第一步重新计算了
注意这里的 $v_k$ 它不是一个 state value。它就是一个值。因此我们可以开始给它任意的值
具体的步骤: 当 $|v_k - v_{k-1}| < \epsilon$ 时,停止迭代. 对于第 $k$ 次迭代执行以下步骤:
- 遍历所有的状态 $s \in \mathcal{S}$
- 对这个状态 $s$
下的所有 action $a \in \mathcal{A}(s)$
计算 action value $q(s,a)$
:
- $q_k(s,a) = \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s,a) v_k(s')$
- 这个式子是直接从定义出发的,即从状态 s 出发,take action a 后的 avg return。
- 统计 Maximum action value: $a^*_k(s) = \arg \max_{a} q_k(s,a)$
- policy update: 更新 $\pi_{k+1}(a|s)$ , 即在 s 状态下执行action a。对应到概率更新就是 $ \pi_{k+1}(a|s) = \begin{cases} 1 & \text{if } a = a^*_k \\ 0 & \text{otherwise} \end{cases} $
- value update: 更新 $v_{k+1}(s)$ , 即在 s 状态下执行action a后的 avg return。对应到 value 更新就是 $v_{k+1}(s) = \max_{a} q_k(s,a)$
注意这里每一步的 policy update 不是必须的。我们可以在 value 收敛后根据最后一次的 value 来更新 policy。 计算 $q_{\pi_k}(s,a)$ 的时候已经蕴含了 policy 即贪心选择回报最大的动作
def value_iteration(
states,
actions,
transition_prob,
gamma,
epsilon,
):
"""
states: list of states
actions: list of actions for one state
transition_prob: p(s', r | s, a)
gamma: discount factor
epsilon: convergence threshold
"""
v = {s: 0 for s in states}
while True:
delta = 0
v_new = {s: 0 for s in states}
for s in states:
v_new[s] = max(
[
sum(
(r + gamma * v[s_next]) * p
for s_next, r, p in transition_prob(s, a)
) # caculate q-value for each action
for a in actions[s]
] # calculate q-value table
)
delta = max(delta, abs(v_new[s] - v[s]))
v = v_new
if delta < epsilon: # convergence check
break
policy = {
s: max( # greedy policy, get maximum q-value action
actions[s],
key=lambda a: sum(
(r + gamma * v[s_next]) * p
for s_next, r, p in transition_prob(s, a)
)
)
for s in states
}
return v, policy
VI Example
我们假设有 $r_{bound} = r_{forbidden} = -1, r_{target} = 1$ ,和 $\gamma = 0.9$ 。
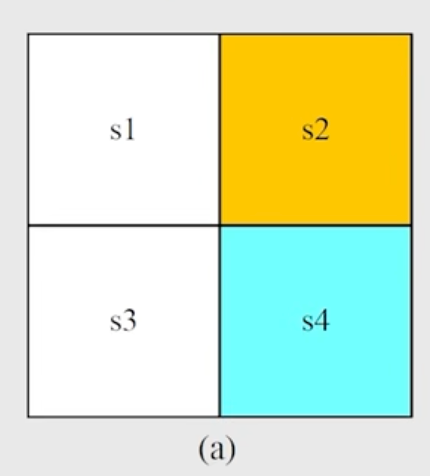
s2: 是forbidden area s4: 是target area
我们要求解这个 grid world 的 optimal policy。
要求解我们需要先打表,得到一个 q-table。也就是每个 q(s,a) 的值。
| q-value | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| $s_1$ | $-1 + \gamma v(s_1)$ | $-1 + \gamma v(s_2)$ | $0 + \gamma v(s_3)$ | $-1 + \gamma v(s_1)$ | $0 + \gamma v(s_1)$ |
| $s_2$ | $-1 + \gamma v(s_2)$ | $-1 + \gamma v(s_2)$ | $1 + \gamma v(s_4)$ | $0 + \gamma v(s_1)$ | $-1 + \gamma v(s_2)$ |
| $s_3$ | $0 + \gamma v(s_1)$ | $1 + \gamma v(s_4)$ | $-1 + \gamma v(s_3)$ | $-1 + \gamma v(s_3)$ | $0 + \gamma v(s_3)$ |
| $s_4$ | $-1 + \gamma v(s_2)$ | $-1 + \gamma v(s_4)$ | $-1 + \gamma v(s_4)$ | $0 + \gamma v(s_3)$ | $1 + \gamma v(s_4)$ |
k = 0 时,我们不妨假设 $v_0(s1) = v_0(s2) = v_0(s3) = v_0(s4) = 0$ 然后我们就可以 q-table 公式来更新 q-value。
| q-value | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| $s_1$ | $-1$ | $-1$ | $\color{red}{0}$ | $-1$ | $\color{red}{0}$ |
| $s_2$ | $-1$ | $-1$ | $\color{red}{1}$ | $0$ | $-1$ |
| $s_3$ | $0$ | $\color{red}{1}$ | $-1$ | $-1$ | $0$ |
| $s_4$ | $-1$ | $-1$ | $-1$ | $0$ | $\color{red}{1}$ |
Step 1: policy update
红字是在对应状态下 q-value 最大的 action。因此我们需要更新我们的 policy。
$$ \pi_{1}(a_5|s_1) = 1 \\ \pi_{1}(a_3|s_2) = 1 \\ \pi_{1}(a_2|s_3) = 1 \\ \pi_{1}(a_5|s_4) = 1 $$Step 2: value update
把最大的 $q_k$ 更新回去:
$$ v_1(s_1) = 0 \\ v_1(s_2) = q_1(s_2, a_3) = 1 \\ v_1(s_3) = q_1(s_3, a_2) = 1 \\ v_1(s_4) = q_1(s_4, a_5) = 1 $$更新完之后的策略如图所示:
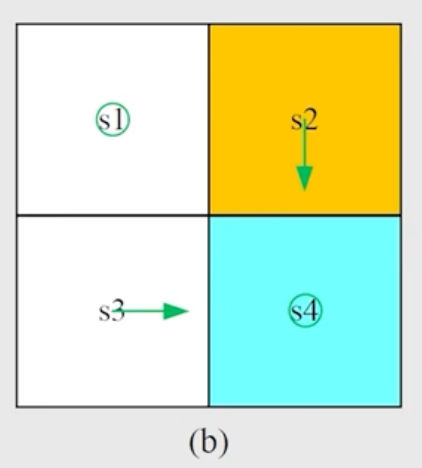
随后我们进行第二轮的迭代,k = 1 时,代入更新过的 $v_1$ 值,重新计算 q-value。
| q-value | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| $s_1$ | $-1+\gamma 0$ | $-1+\gamma 1$ | $\color{red}{0+\gamma 1}$ | $-1+\gamma 0$ | $0+\gamma 0$ |
| $s_2$ | $-1+\gamma 1$ | $-1+\gamma 1$ | $\color{red}{1+\gamma 1}$ | $0+\gamma 0$ | $-1+\gamma 1$ |
| $s_3$ | $0+\gamma 0$ | $\color{red}{1+\gamma 1}$ | $-1+\gamma 1$ | $-1+\gamma 1$ | $0+\gamma 1$ |
| $s_4$ | $-1+\gamma 1$ | $-1+\gamma 1$ | $-1+\gamma 1$ | $0+\gamma 1$ | $\color{red}{1+\gamma 1}$ |
Step 1: policy update 然后我们更新 policy:
$$ \pi_{2}(a_3|s_1) = 1 \\ \pi_{2}(a_3|s_2) = 1 \\ \pi_{2}(a_2|s_3) = 1 \\ \pi_{2}(a_5|s_4) = 1 $$Step 2: value update
$$ v_2(s_1) = \gamma 1 \\ v_2(s_2) = q_2(s_2, a_3) = 1 + \gamma 1 \\ v_2(s_3) = q_2(s_3, a_2) = 1 + \gamma 1 \\ v_2(s_4) = q_2(s_4, a_5) = 1 + \gamma 1 $$更新过的策略如图所示:
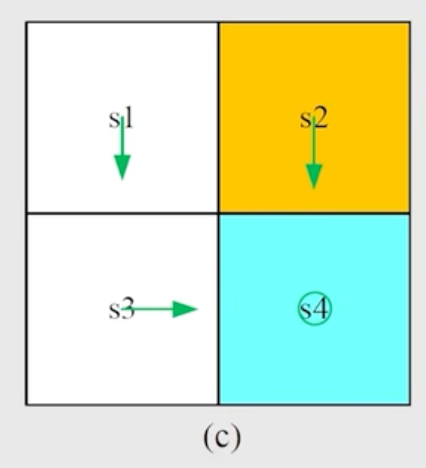
继续迭代下去我们会发现 $v_k$ 和 $v_{k-1}$ 这两个向量的差的 norm 变化已经很小了,我们可以认为它收敛了。
Policy iteration
最开始任意给定一个策略,随后对它不断进行 policy evaluation 和 policy improvement 直到收敛为止。
- Step 1: policy evaluation
- 给定一个策略 $\pi$ ,我们可以列出来在这个policy 下所有的 bellman equation。
- 求解这个 bellman equation,我们可以得到每个状态的 state value
- 有了这个 state value,我们就可以评估这个策略的好坏。 $ v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k}v_{\pi_{k-1}} $
- 对于这个求解,我们需要使用迭代法 $ v_{\pi_k}^{j+1} = r_{\pi_k} + \gamma P_{\pi_k}v_{\pi_k}^j, \ j = 0, 1, 2, ... $
- 一开始我们对 $v_{\pi_k}$ 有一个猜测,然后不断迭代进行计算,直到收敛为止。
- Step 2: policy improvement
- 求出来的 $v_{\pi_k}$ 我们求解对于 $\pi_{k+1}$ 的优化问题然后得到一个更好的 policy $\pi_{k+1}$ $ \pi_{k+1} = \arg \max_{\pi}(r_{\pi} + \gamma P_{\pi}v_{\pi_k}) $
- 重复以上步骤直到收敛为止。
def policy_iteration(
states,
actions,
transition_prob,
gamma,
epsilon,
):
"""
states: list of states
actions: list of actions for one state
transition_prob: p(s', r | s, a)
gamma: discount factor
epsilon: convergence threshold
"""
v = {s: 0 for s in states}
pi = {s: actions[s][0] for s in states}
while True:
# policy evaluation
while True:
delta = 0
v_new = v.copy()
for s in states:
a = pi[s]
v_new[s] = sum(
(r + gamma * v[s_next]) * p
for s_next, r, p in transition_prob(s, a)
)
delta = max(delta, abs(v_new[s] - v[s]))
v = v_new
if delta < epsilon:
break
# policy improvement
stable = True
for s in states:
best_action = max(
actions[s],
key=lambda a: sum(
(r + gamma * v[s_next]) * p
for s_next, r, p in transition_prob(s, a)
)
)
if best_action != pi[s]:
pi[s] = best_action
stable = False
if stable:
break
return v, pi
example
 $$
r_{bound} = -1, r_{target} = 1
\\ \gamma = 0.9
\\ Action\ set: {a_{l}, a_{r}, a_0}
$$
$$
r_{bound} = -1, r_{target} = 1
\\ \gamma = 0.9
\\ Action\ set: {a_{l}, a_{r}, a_0}
$$对于这个例子我们怎么run policy iteration?
iteration k = 0:
Step 1: policy evaluation 就是算 $v_{\pi_0}$ ,也就是求 bellman equation 的解。 直观上可以直接得出来
$$ v_{\pi_0}(s_1) = -1 + \gamma v_{\pi_0}(s_1) = -10 \\ v_{\pi_0}(s_2) = 0 + \gamma v_{\pi_0}(s_1) = -9 $$但同时我们也可以用迭代法来求解:
$$ 假设\ v_{\pi_0}^{(0)}(s_1) = v_{\pi_0}^{(0)}(s_2) = 0 \\ v_{\pi_0}^{(1)}(s_1) = -1 + \gamma v_{\pi_0}^{(0)}(s_1) = -1 \\ v_{\pi_0}^{(1)}(s_2) = 0 + \gamma v_{\pi_0}^{(0)}(s_1) = 0 \\ v_{\pi_0}^{(2)}(s_1) = -1 + \gamma v_{\pi_0}^{(1)}(s_1) = -1.9 \\ v_{\pi_0}^{(2)}(s_2) = 0 + \gamma v_{\pi_0}^{(1)}(s_1) = -0.9 \\ ... $$我们可以写一个 python 代码来求解:
v_pi_s_1 = v_pi_s_2 = 0
iteration = 100
gamma = 0.9
for i in range(0, iteration):
v_pi_s_1 = -1 + gamma * v_pi_s_1
v_pi_s_2 = 0 + gamma * v_pi_s_1
print(f"iteration {i}: v_pi_s_1 = {v_pi_s_1:.2f}, v_pi_s_2 = {v_pi_s_2:.2f}")
以下是迭代100次后的结果:
iteration 0: v_pi_s_1 = -1.00, v_pi_s_2 = -0.90
iteration 1: v_pi_s_1 = -1.90, v_pi_s_2 = -1.71
iteration 2: v_pi_s_1 = -2.71, v_pi_s_2 = -2.44
...
iteration 33: v_pi_s_1 = -9.72, v_pi_s_2 = -8.75
iteration 34: v_pi_s_1 = -9.75, v_pi_s_2 = -8.77
...
iteration 39: v_pi_s_1 = -9.85, v_pi_s_2 = -8.87
iteration 40: v_pi_s_1 = -9.87, v_pi_s_2 = -8.88
...
iteration 70: v_pi_s_1 = -9.99, v_pi_s_2 = -8.99
iteration 71: v_pi_s_1 = -9.99, v_pi_s_2 = -9.00
iteration 72: v_pi_s_1 = -10.00, v_pi_s_2 = -9.00
iteration 73: v_pi_s_1 = -10.00, v_pi_s_2 = -9.00
...
iteration 99: v_pi_s_1 = -10.00, v_pi_s_2 = -9.00
Step 2: policy improvement
这一步和 value iteration 的 policy update 是一样的。首先我们需要有一个 q-value 的表格。
recall: action value 是指从某个状态出发,take action a 后的 avg return。
| $q_{\pi_k}(s,a)$ | $a_\ell$ | $a_0$ | $a_r$ |
|---|---|---|---|
| $s_1$ | $-1 + \gamma v_{\pi_k}(s_1)$ | $0 + \gamma v_{\pi_k}(s_1)$ | $1 + \gamma v_{\pi_k}(s_2)$ |
| $s_2$ | $0 + \gamma v_{\pi_k}(s_1)$ | $1 + \gamma v_{\pi_k}(s_2)$ | $-1 + \gamma v_{\pi_k}(s_2)$ |
然后把上一步的 $v_{\pi_k}$ 代入进去,我们就可以得到 q-value 的表格。
| $q_{\pi_0}(s,a)$ | $a_\ell$ | $a_0$ | $a_r$ |
|---|---|---|---|
| $s_1$ | -10 | -9 | $\red{-7.1}$ |
| $s_2$ | -9 | $\red{-7.1}$ | -9.1 |
其中红色的部分是 q-value 最大的部分。因此我们就可以更新 policy。
$$ \pi_{1}(a_r|s_1) = 1 \\ \pi_{1}(a_0|s_2) = 1 $$然后我们就可以继续迭代。但是对于这个例子我们发现一次迭代已经收敛了。因此我们就可以得到最优策略。
Truncated policy iteration
截断策略迭代(Truncated Policy Iteration)是值迭代和策略迭代的一般化推广,旨在权衡收敛速度与计算效率。如果将两个算法对齐:
| Steps | Policy Iteration | Value Iteration | Comments |
|---|---|---|---|
| (1) Policy | $\pi^{(0)}$ | N/A | |
| (2) Value | $v_{\pi^{(0)}} = r_{\pi^{(0)}} + \gamma P_{\pi^{(0)}} v_{\pi^{(0)}}$ | $\color{red}{v^{(0)} := v_{\pi^{(0)}}}$ | 人为赋予 VI 的相同初始值,便于比较 |
| 3) Policy: | $\pi_1 = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_0})$ | $\pi_1 = \arg\max_\pi (r_\pi + \gamma P_\pi v_0)$ | 这一步的操作和结果一模一样 |
| 4) Value: | $v_{\pi_1} = r_{\pi_1} + \gamma P_{\pi_1} v_{\pi_1}$ | $\color{red}{v_1 = r_{\pi_1} + \gamma P_{\pi_1} v_0}$ | $v_{\pi_1} \geq v_1$ since $v_{\pi_1} \geq v_{\pi_0}$ |
| 5) Policy: | $\pi_2 = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_1})$ | $\pi_2' = \arg\max_\pi (r_\pi + \gamma P_\pi v_1)$ | 接下来差距越变越大 |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ |
为了便于对齐比较,我们把第二步 VI 的值赋成和 PI 中计算出来的值。
然后可以看到,关键的分歧在于 (4) Value 步骤时,策略迭代采用的是一个内嵌迭代去多次更新了状态值($v_{\pi_1}$ ),而值迭代只采用一次更新得到了新状态值($v_1$ )。
那我们是否取一个中间的迭代次数,比如 10 次,然后进行 policy improvement?答案是可以的。这就是截断策略迭代。这三种方式都是可以收敛的。证明略去。
因此我们可以知道 truncated policy iteration 是 value iteration 和 policy iteration 的统一化表达方式:
- 当迭代次数为 1 时,就是 value iteration
- 当迭代次数为无穷大时,就是 policy iteration
- 当迭代次数为有限时,就是 truncated policy iteration