CS5446 2. Bellman equation
Notes for CS5446 Reinforcement Learning.
State value
State value 全称叫 State Value Function,用 $v_\pi(s)$ 表示。它本质就是某个过程的累积回报的期望。
$$ v_\pi(s) = \mathbb{E}_{\pi}[G_t | S_t = s] $$- 其中 $G_t$ 是累积回报,$\pi$ 是策略,$S_t$ 是状态。
- 这个 $v_\pi(s)$ 是针对 s 的一个函数,不同的 s 出发得到的trajectory 不同,所以期望值不同。这个函数表达的是,从s出发的所有轨迹的return的期望(平均值)。
- 它是基于策略 $\pi$ 的,不同的策略会有不同的状态值。不同的策略会得到不同的轨迹。我们可以认为这个函数它接受两个变量:$v(s, \pi)$
Return 和 State value 的关系:
Return 是对单个 trajectory 的累积回报。而 State value 是对所有 trajectory 的累积回报的期望。
如果一个状态出发只能得到一个 trajectory,那么 Return 和 State value 是相等的。
example
我们有一个网格
| s1 | s2 |
| s3 | s4 |
Policy:
1. pi_1:
- s1 -> s2
- s2 -> s4
- s4 -> s4
2. pi_2:
- s1 -> s3
- s3 -> s4
- s4 -> s4
3. pi_3:
- s1 -> s2: 50%
- s1 -> s3: 50%
- s3 -> s4
- s2 -> s4
- s4 -> s4
Reward:
- s1 -> s2: -1
- s1 -> s3: 0
- s3 -> s4: 1
- s2 -> s4: 1
- s4 -> s4: 1
计算 $v_\pi(s1)$ :
$$ \begin{aligned} v_{\pi}(s4) &= 1 + \gamma v_{\pi_1}(s4) \\ &= 1 + \gamma + \gamma^2 v_{\pi_1}(s4) \\ &= 1 + \gamma + \gamma^2 + \gamma^3 + \cdots \\ &= \frac{1}{1-\gamma} \\ v_{\pi_1}(s1) &= -1 + \gamma v_{\pi_1}(s2) \\ &= -1 + \gamma (1 + \gamma v_{\pi_1}(s4)) \\ &= -1 + \frac{\gamma}{1-\gamma} \\ v_{\pi_2}(s1) &= 0 + \gamma v_{\pi_2}(s3) \\ &= 0 + \gamma (1 + \gamma v_{\pi_2}(s4)) \\ &= \frac{\gamma}{1-\gamma} \\ v_{\pi_3}(s1) &= 0.5 \cdot v_{\pi_1}(s1) + 0.5 \cdot v_{\pi_2}(s1) \\ &= 0.5 \cdot \left(-1 + \frac{\gamma}{1-\gamma}\right) + 0.5 \cdot \left(\frac{\gamma}{1-\gamma}\right) \\ &= -0.5 + \frac{\gamma}{1-\gamma} \end{aligned} $$$v_\pi(s1)$ 就是上面三个策略的集合。
Bellman equation
$$ G_t = R_{t+1} + \gamma G_{t+1} $$这个公式很直观:当前的回报等于当前的奖励加上折扣后的未来回报。考虑到 State value 的定义, 我们可以得到:
$$ \begin{aligned} v_\pi(s) &= \mathbb{E}_{\pi}[G_t | S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1}| S_t = s] + \gamma \mathbb{E}_{\pi}[G_{t+1} | S_t = s] \end{aligned} $$for the first term:
$$ \begin{aligned} & \mathbb{E}_{\pi}[R_{t+1}| S_t = s] \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) \mathbb{E}_[R_{t+1}| S_t = s, A_t = a] \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) \sum_{r} p(r|s,a)r \end{aligned} $$第一个等式表示:
- 在策略 $\pi$ 下,在状态 s 下,take action a 有一个概率
- 在t时刻,s状态下,take action a 后的期望奖励。
- 由于动作是一个集合,所以需要叠加所有动作的期望奖励。因此要取期望
第二个等式是对期望的展开:
- 在s这个状态下,take action a 后获取 r reward 的概率 是 $p(r|s,a)$
- 我们要求期望,所以需要对所有可能的 r 进行叠加。
the first term is the mean of immediate reward.
for the second term:
$$ \begin{aligned} & \mathbb{E}_{\pi}[G_{t+1} | S_t = s] \\ &= \sum_{s' \in \mathcal{S}} p(s'|s) \mathbb{E}[G_{t+1} | S_t = s, S_{t+1} = s'] \\ &= \sum_{s' \in \mathcal{S}} p(s'|s) \mathbb{E}[G_{t+1} | S_{t+1} = s'] \\ &= \sum_{s' \in \mathcal{S}} p(s'|s) v_\pi(s') \\ &= \sum_{s' \in \mathcal{S}} v_\pi(s') \sum_{a \in \mathcal{A}(s')} \pi(a|s) p(s'|s,a) \end{aligned} $$- 第一个等式是对期望的展开:在状态从s 变为 s’ 的时候有一个概率,针对所有可能的状态变化,求Return的期望。
- 第二个等式相对于第一个用力 markov property,未来只取决于当前状态,与过去无关。
- $\mathbb{E}[G_{t+1} | S_{t+1} = s']$ 说的是在s’状态下,从s’出发的Return的期望。其实就是 state value
- 第四个等式说的是,在s状态下,想改变状态需要 take action. take action 需要依照策略 $\pi$ 来选择。因此要对所有可能的 action 进行叠加。
the second term is the mean of future return.
这里所有的替换目的都是为了把所有的位置量都由上一章节提到的 MDP 中的变量来表示:
- Decision policy,$\pi(a|s)$
- State value, $v_\pi(s')$
- State transition probability, $p(s'|s,a)$
- Reward probability, $p(r|s,a)$
后续 Decision policy 和 State value 将成为我们优化的对象, State transition probability 和 Reward probability,被称为 dynamic model。
- 如果dynamic model 已知,并基于他们求解 State value,则称为 model-based 的算法
- 否则称为 model-free
综合起来,我们得到了 Bellman equation:
$$ \begin{aligned} \red{v_\pi(s)} &= \mathbb{E}_{\pi}[G_t | S_t = s] \\ &= \mathbb{E}_{\pi}[R_{t+1}| S_t = s] + \gamma \mathbb{E}_{\pi}[G_{t+1} | S_t = s] \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} \red{ v_\pi(s')} \sum_{a \in \mathcal{A}(s')} \pi(a|s) p(s'|s,a) \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) \Big[ \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s,a) \red{ v_\pi(s')} \Big] \end{aligned} $$- 这个公式叫做 bellman equation。
- 它描述了不同状态的 state value 之间的关系。(红色表示)
- 这个公式对所有状态都成立
- 每个状态都有一个形如这样的式子
deterministic Example
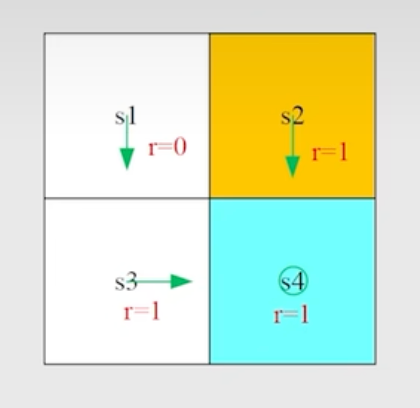
Q:针对这个例子写出所有的 Bellman equation。
首先我们有:
$$ \red{v_\pi(s)} = \sum_{a \in \mathcal{A}(s)} \pi(a|s) \Big[ \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s,a) \red{ v_\pi(s')} \Big] $$但是其实我们不需要代入,或者说对于这个例子直观上是很简单的,即
$$ v_\pi(s_1) = 0 + \gamma v_\pi(s_3) $$即 immediate reward (0) + discounted future return ($\gamma * v_\pi(s3)$ )
同理:
$$ \begin{aligned} v_\pi(s_2) &= 1 + \gamma v_\pi(s_4) \\ v_\pi(s_3) &= 1 + \gamma v_\pi(s_4) \\ v_\pi(s_4) &= 1 + \gamma v_\pi(s_4) \end{aligned} $$这些方程组是可以求解的,即我们可以算出来每个 state value
$$ \begin{aligned} v_\pi(s_4) &= \frac{1}{1-\gamma} \\ v_\pi(s_3) &= v_\pi(s_4) = \frac{1}{1-\gamma} \\ v_\pi(s_2) &= v_\pi(s_4) = \frac{1}{1-\gamma} \\ v_\pi(s_1) &= 0 + \gamma v_\pi(s_3) = \frac{\gamma}{1-\gamma} \end{aligned} $$如果 $\gamma = 0.9$ ,那么:
$$ \begin{aligned} v_\pi(s_4) &= \frac{1}{1-0.9} = 10 \\ v_\pi(s_3) &= v_\pi(s_4) = 10 \\ v_\pi(s_2) &= v_\pi(s_4) = 10 \\ v_\pi(s_1) &= 0 + 0.9 \cdot 10 = 9 \end{aligned} $$stochastic Example
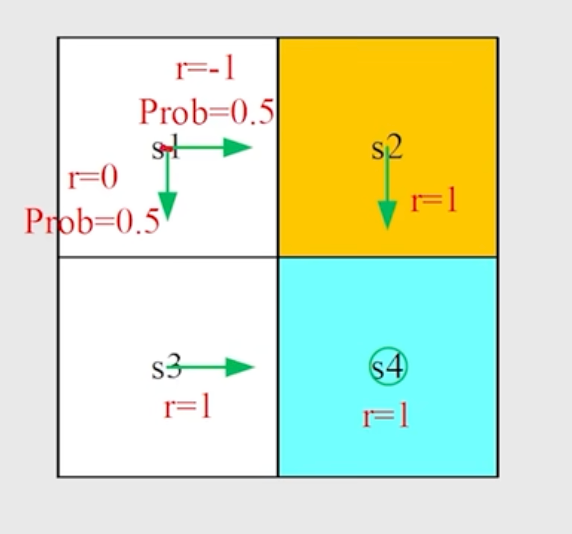
同样写出所有的 Bellman equation。
$$ \begin{aligned} v_\pi(s_4) &= 1 + \gamma v_\pi(s_4) = \frac{1}{1-\gamma} \\ v_\pi(s_3) &= 1 + \gamma v_\pi(s_4) = \frac{1}{1-\gamma} \\ v_\pi(s_2) &= 1 + \gamma v_\pi(s_4) = \frac{1}{1-\gamma} \\ v_\pi(s_1) &= 0.5 \cdot (0 + \gamma v_\pi(s_3)) + 0.5 \cdot (-1 + \gamma v_\pi(s_2)) \\ &= \frac{\gamma}{1-\gamma} - 0.5 \end{aligned} $$如果 $\gamma = 0.9$ ,那么:
$$ \begin{aligned} v_\pi(s_4) &= \frac{1}{1-0.9} = 10 \\ v_\pi(s_3) &= v_\pi(s_4) = 10 \\ v_\pi(s_2) &= v_\pi(s_4) = 10 \\ v_\pi(s_1) &= 9 - 0.5 = 8.5 \end{aligned} $$评估以上两种策略
第二种 stochastic 策略的 state value 更低 (8.5 < 9),因此第一种策略更好。
Policy Evaluation
- 给定一个策略 $\pi$ ,我们可以列出来在这个policy 下所有的 bellman equation。
- 求解这个 bellman equation,我们可以得到每个状态的 state value
- 有了这个 state value,我们就可以评估这个策略的好坏。
以上过程就叫做 Policy Evaluation。换句话说 policy evaluation 就是求解 bellman equation 算出来 state value。我们有两种方式来求解:
- 解析法
- 迭代法
解析法通常需要求解线性方程组,通常会将 bellman 公式变成矩阵的形式进行求解。但是计算量略大。我们一般使用迭代法来求解。
Iterative Policy Evaluation
$$ v_{k+1} = r_{\pi} + \gamma P_{\pi}v_{k} $$- $v_{k+1}$ 是第 $k+1$ 次迭代的结果
- $v_{k}$ 是第 $k$ 次迭代的结果
- $r_{\pi}$ 是策略 $\pi$ 下的期望即时奖励
- $P_{\pi}$ 是策略 $\pi$ 下的状态转移矩阵
这个迭代法的思想是,经过若干步迭代后,state value 会收敛到真实值 $v_\pi$ 。
Action Value
和 State value 的区别:
- State value 是从某个状态出发得到的 avg return
- Action value 是从某个状态出发,take action a 得到的 avg return
Action value 存在的意义是帮助我们对策略进行评估。因为策略就是在某个状态下选择一个 action。action value可以帮助我们做评估。
$$ q_\pi(s,a) = \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a] $$公式表示:从状态 s 出发,take action a 后的 avg return。从公式直接推导可以得到:
$$ \begin{aligned} v_\pi(s) &= \mathbb{E}_{\pi}[G_t | S_t = s] \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a] \\ &= \sum_{a \in \mathcal{A}(s)} \pi(a|s) q_\pi(s,a) \end{aligned} $$从 bellman equation 可以得到:
$$ v_\pi(s) = \sum_{a \in \mathcal{A}(s)} \pi(a|s) \red{ \Big[ \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s,a) v_\pi(s') \Big]} $$所以另一种形式的 action value 就是:
$$ q_\pi(s,a) = \sum_{r} p(r|s,a)r + \gamma \sum_{s' \in \mathcal{S}} p(s'|s,a) \red{ v_\pi(s')} $$比较两种形式的 action value,我们可以得到:
- 如果我们知道了所有的 action value 那么我们就可以求解 state value (求平均)
- 如果我们知道了所有的 state value 那么我们就可以求解 action value
Example
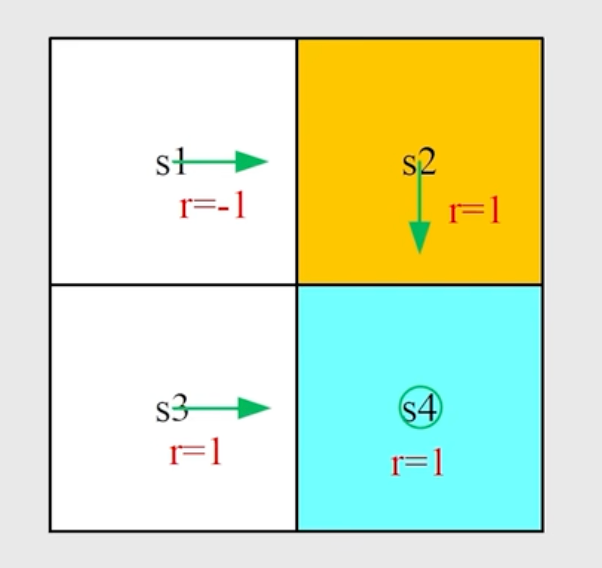
Q:针对 state s1 写出所有的 action value。
$$ \begin{aligned} q_\pi(s_1,a_2) &= -1 + \gamma v_\pi(s_2) \\ &= -1 + \gamma \cdot (1 + \gamma v_\pi(s_4)) \\ &= -1 + \gamma \cdot (1 + \gamma \frac{1}{1-\gamma}) \\ &= \frac{2\gamma - 1}{1-\gamma} \end{aligned} $$我们假设向右是 $a_2$ 向下是 $a_3$ 向上是 $a_1$ 向左是 $a_4$
这个式子是直接从定义出发的,即从状态 s1 出发,take action a2 后的 avg return。
这里的 avg return 就是 immediate reward 加上 discounted future return。
注意这里的其他的 action value 不是 0
$$ \begin{aligned} q_\pi(s_1,a_1) &= -1 + \gamma v_\pi(s_1) \\ q_\pi(s_1,a_3) &= 0 + \gamma v_\pi(s_3) \\ q_\pi(s_1,a_4) &= -1 + \gamma v_\pi(s_1) \\ q_\pi(s_1,a_5) &= 0 + \gamma v_\pi(s_1) \end{aligned} $$我们这里有一个假设,超越边界会拿 -1 的reward,并被弹回当前状态。