CS5446 1. Concepts
Notes for CS5446 Reinforcement Learning.
Grid world example
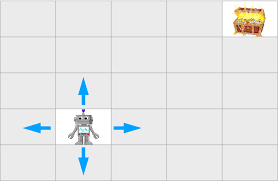
- 机器人需要在网格世界中找到宝藏
- 网格的类型:
- Accessible:机器人可以到达的网格
- Forbidden:机器人不能到达的网格
- Target cell:机器人需要到达的网格
- boundary:机器人不能离开的网格
- 机器人可以执行的动作:
- move up
- move down
- move left
- move right
RL 的任务是找到一个 good way to the target cell.
什么才算好:
- 不要撞到forbidden cell
- 尽快到达target cell
- 不要超越 boundary
State
State 是 Agent 相对于 Environment 的一个状态。在grid world中,State 就是机器人当前所在的网格。
更加复杂的例子 State 可能包括速度,方向,时间,等等。
State space is the set of all possible states.
$$ \mathcal{S} = \{s_1, s_2, \ldots, s_n\} $$Action
在某个状态下可以执行的动作。在 Grid world 中,Action 就是机器人可以执行的上下左右移动。
Action space is the set of all possible actions for one state.
$$ \mathcal{A(s_i)} = \{a_1, a_2, \ldots, a_n\} $$State transition
执行某个动作后,状态发生了变化。这个过程就叫状态转移。它定义了 Agent 和环境的交互行为。状态转移需要我们提前进行定义。
Tabular representation
我们可以使用一种 tabular representation 来表示状态转移。实际上是一种表格,比如在 grid world 中,我们可以使用如下表格来表示状态转移:
在九宫格中,每个格子代表一个状态:
| s1 | s2 | s3 |
| s4 | s5 | s6 |
| s7 | s8 | s9 |
叠加动作我们可以有以下表格:
| state | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| s1 | s1 | s2 | s4 | s1 | s1 |
| s2 | s2 | s3 | s5 | s1 | s2 |
| s3 | s3 | s3 | s6 | s2 | s3 |
| s4 | s1 | s5 | s7 | s4 | s4 |
| s5 | s2 | s6 | s8 | s4 | s5 |
| s6 | s3 | s6 | s9 | s5 | s6 |
| s7 | s4 | s8 | s7 | s7 | s7 |
| s8 | s5 | s9 | s8 | s7 | s8 |
| s9 | s6 | s9 | s9 | s8 | s9 |
这种表格只能表示 deterministic 的情况。
State transition probability representation
$$ p(s2|s1,a1) = 1 $$目前我在 s1,执行 a1 动作,我到达 s2 的概率是 1。
也可以用来表示 stochastic 的情况。
Policy
$\pi$ 在RL中指策略,我们一般用条件概率表示策略,比如:
对于 state $s_1$ 所有的策略集合是:
$$ \pi(a1|s1) = 0 \pi(a2|s1) = 0.5 \pi(a3|s1) = 0.5 \pi(a4|s1) = 0 \pi(a5|s1) = 0 $$所有的策略集合的概率和是 1。所以我们也可以用一个概率分布来表示策略。当某个策略的概率是 1 的时候,那它就是 deterministic 的。
条件概率的表示方式更一般化。策略也可以用 tabular representation 来表示, 比如:
| state | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| s1 | 0 | 0.5 | 0.5 | 0 | 0 |
| s2 | 0 | 0 | 1 | 0 | 0 |
| s3 | 0 | 0 | 0 | 1 | 0 |
| s4 | 0 | 1 | 0 | 0 | 0 |
| s5 | 0 | 0 | 1 | 0 | 0 |
| s6 | 0 | 0 | 1 | 0 | 0 |
| s7 | 0 | 1 | 0 | 0 | 0 |
| s8 | 0 | 1 | 0 | 0 | 0 |
| s9 | 0 | 0 | 0 | 0 | 1 |
Reward
在 action 之后我们得到的一个实数,通常正数代表鼓励,负数代表惩罚。比如在 grid world 中,我们可以使用如下表格来表示奖励:
- $r_{bound} = -1$ 表示进入 boundary 的惩罚
- $r_{target} = 100$ 表示到达 target cell 的奖励
Reward 通常是人类和机器的交互边界,我们可以通过调整 reward 来控制机器的行为。
我们同样可以用 tabular representation 来表示 reward,比如:
| state | a1 (upwards) | a2 (rightwards) | a3 (downwards) | a4 (leftwards) | a5 (unchanged) |
|---|---|---|---|---|---|
| s1 | $r_{bound}$ | 0 | 0 | $r_{bound}$ | 0 |
| s2 | $r_{bound}$ | 0 | 0 | 0 | 0 |
| s3 | $r_{bound}$ | $r_{bound}$ | $r_{forbid}$ | 0 | 0 |
| s4 | 0 | 0 | $r_{forbid}$ | $r_{bound}$ | 0 |
| s5 | 0 | $r_{forbid}$ | 0 | 0 | 0 |
| s6 | 0 | $r_{bound}$ | $r_{target}$ | 0 | $r_{forbid}$ |
| s7 | 0 | 0 | $r_{bound}$ | $r_{bound}$ | $r_{forbid}$ |
| s8 | 0 | $r_{target}$ | $r_{bound}$ | $r_{forbid}$ | 0 |
| s9 | $r_{forbid}$ | $r_{bound}$ | $r_{bound}$ | 0 | $r_{target}$ |
但是这种方式只能表示 deterministic 的情况。
一般地我们可以用条件概率来表示 reward,比如:
$$ p(r = -1|s_1, a_1) = 1 $$表示在 s1 状态下执行 a1 动作后,奖励为 -1 的概率是 1。
Trajectory
Trajectory 是 State action reward 的序列链。不同的 policy 会得到不同的 trajectory。
有终结的 trajectory 是 episode。有终结状态的任务叫 episodic task。没有终结状态的任务叫 continuous task。
Return
Return 是 Trajectory 的累计奖励。return 可以用来评估 policy 的好坏
discount rate $\gamma$ 的范围是 [0, 1]
$$ G_t = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \ldots $$其中 $\gamma$ 是折扣因子,表示未来的奖励对当前奖励的折扣。
- $\gamma$ is close to 0, 近未来的回报更重要
- $\gamma$ is close to 1, 远未来的回报更重要
折扣因子可以帮助我们收敛 Return 的计算。
MDP (Markov Decision Process)
MDP 是 RL 的核心概念。它是一个四元组:
$$ MDP = (S, A, P, R) $$你可以用递归的方式来解释 MDP:
- M: Markov Property
- 未来只取决于当前状态,与过去无关. 换句话说,当前的状态就可以推导出未来的状态了。一个反例是红绿灯,如果状态是亮灯的颜色,而当前状态是黄灯,我们无法推出未来亮灯的颜色(可能是红灯也可能是绿灯)
- D: Decision policy,$\pi(a|s)$ 换句话说一个MDP 需要定义 policy 来约束动作的选择。
- P: Process:也就是说一个 MDP 需要定义状态转移,那么就需要以下的信息:
- Set:
- State Set: $\mathcal{S}$
- Action Set: $\mathcal{A}(s)$
- Reward Set: $\mathcal{R}(s, a)$
- Probability Distribution:
- State Transition Probability: $p(s'|s,a)$
- Reward Probability: $p(r|s,a)$
- Set:
MP, MRP, MDP 的关系
- MP: $(S, P)$ , 只考虑状态和状态转移概率的集合
- MRP: $(S, P, R)$ ,在 MP 基础上给了状态转移时的奖励集合
- MDP: $(S, A, P, R)$ ,在 MRP 基础上给了动作集合